#3 On consistency protocols for LLM-based solutions
Imagine a world where the Library of Alexandria never burned down. The repository of knowledge, once considered the brain of the ancient world, might have pushed humanity into technological advancements centuries before our time. This thought experiment isn't merely about lost knowledge; it illustrates the impact of some decisions and events on the course of human history, relative to the highly sensitive dependence on initial conditions found in chaos theory.

I've been reading "Distributed Systems" by Maarten van Steen and Andrew S. Tanenbaum for the last few months. And you could get a free PDF copy with the 4th edition directly from the authors by the link. In the 7 Chapter, important concepts of consistency and replication are covered. It starts with a discussion what are the pros and cons and then different consistency models (data/client-centric), replica management, and consistency protocols are covered.
During the same period with the teams, we finished quite a few projects where the solutions were centered around top-of-the-market LLMs. These ranged from developing "analyst assistants" that elicit insights from structured data to crafting recommendation engines that draw from diverse data sources. We've also worked on making sense of highly unstructured, domain-specific information—think mountains of PDFs—turning them into dependable resources for users through chats powered by technologies like RAGs boosted with Knowledge Graphs.
Most of the projects involved code generation (SQL and/or Python) to achieve at least some stability and control over the results. If you have ever played with any LLM you know that even with a set of preventive measures its faithfulness is an issue. It just tries so hard to please you so if you don't decompose the task on more or less controllable bits you will be easily screwed. And you won't even notice it. Trust me.
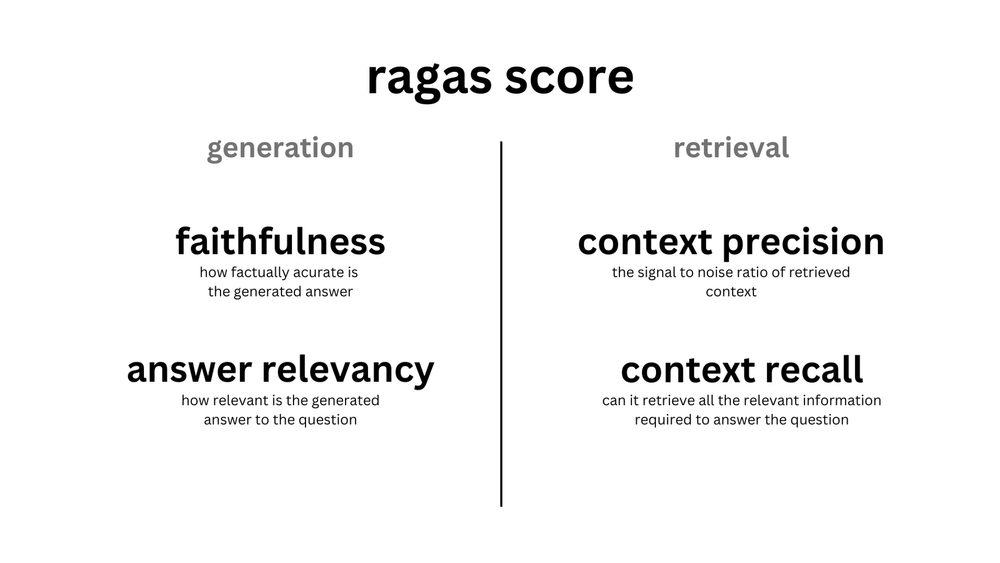
Also, there are a few popular evaluation frameworks (such as RAGAS (on the schema below), DeepEval, OpenAIEvals, TruLens, and many others). I would argue, that setting them up might be more important than the specific model version you select for your PoC.
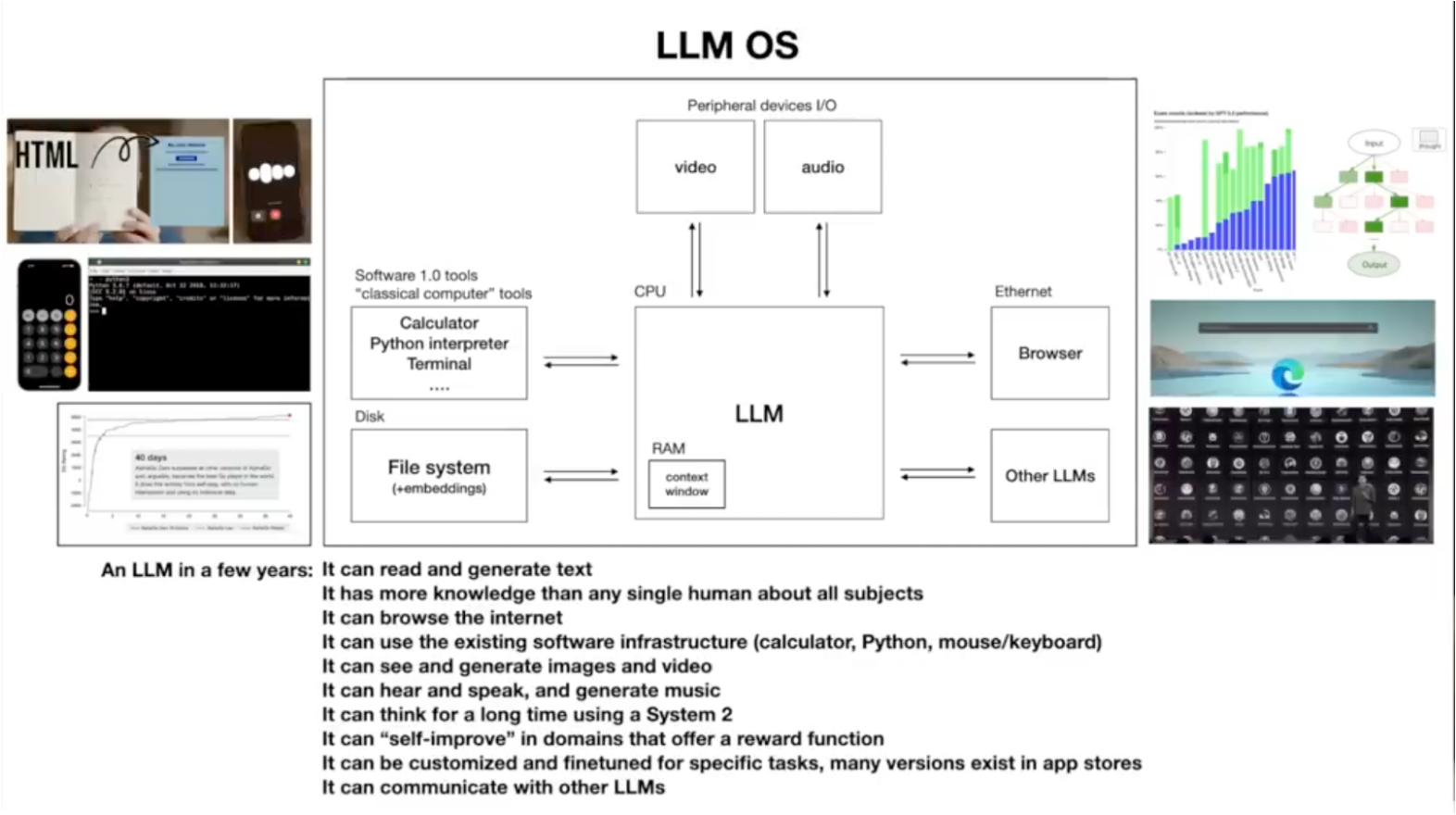
Reading about consistency protocols got me thinking, AI is moving in leaps toward agents and if you watched Andrew Karpaty's already old video you will recognize the image below with the LLM OS concept. It all pushed me from the usual self-consistency on the prompt levels, but more towards consistency as an important characteristic of the distributed AI-based solution as a whole.
But why are consistency protocols so crucial? And how can concepts like the consistency unit (conit) aid in this context? In a similar manner to distributed systems, AI-enhanced solutions are inherently prone to divergence and lack full stability and reliability. We just have to agree on what is acceptable and how to achieve that -> to form a model and describe its implementation in the form of a protocol.
In the book, a set of valuable concepts were laid down such as continuous (keeping the numerical deviation within bounds), sequential (order of events), and causal consistencies concerning data-centric modes. Given the maturity of this field and that this knowledge was not burnt out, let us look at the specific very popular task such as RAG and design an appropriate consistency model in the next piece.